Music thumbnailing
A couple of days ago, I read an interesting paper about a new AI algorithm that can summarize long texts. This is an attempt to solve the problem of tl;dr texts, meaning “too long, didn’t read”.
The article reminded me that the same problem exists for music, in which case it would probably be tl;dl: “too long, didn’t listen”. I was interested in this topic back when I wrote my master’s thesis about short-term music recognition. One way to overcome the challenge of listening through full music tracks is by creating music “thumbnails”. That is, a compact representation of the most salient parts of the music in question. This is not a trivial task, of course, and lots of research have gone into it over the years. Strangely, though, I haven’t seen any of the many suggested algorithms implemented in any commercial service (so far).
Shortening Bolero
I didn’t delve very deep into the topic, but I experimented with modifying a recording of Ravel’s Bolero in my thesis. First, I thought of doing a time compression of a piece that would preserve the overall form and some of the timbral qualities. A test of this was done by compressing Ravel’s Bolero, with a phase vocoder, from 15 minutes to 15 seconds (warning: starts soft and ends loud):
Even though it might be possible to understand the musical content and changing timeless qualities from this example, such a method hardly gives a good representation of what I think is perceptually important in this piece: rhythm, melody, and timbre. A better way might be to cut out short pieces of the entire piece. Since it has been argued that short excerpts are perceptually significant, such a collection of short segments could tell a great deal about a song. Trying to do this automatically I made a Max patch that plays certain segments of a song.
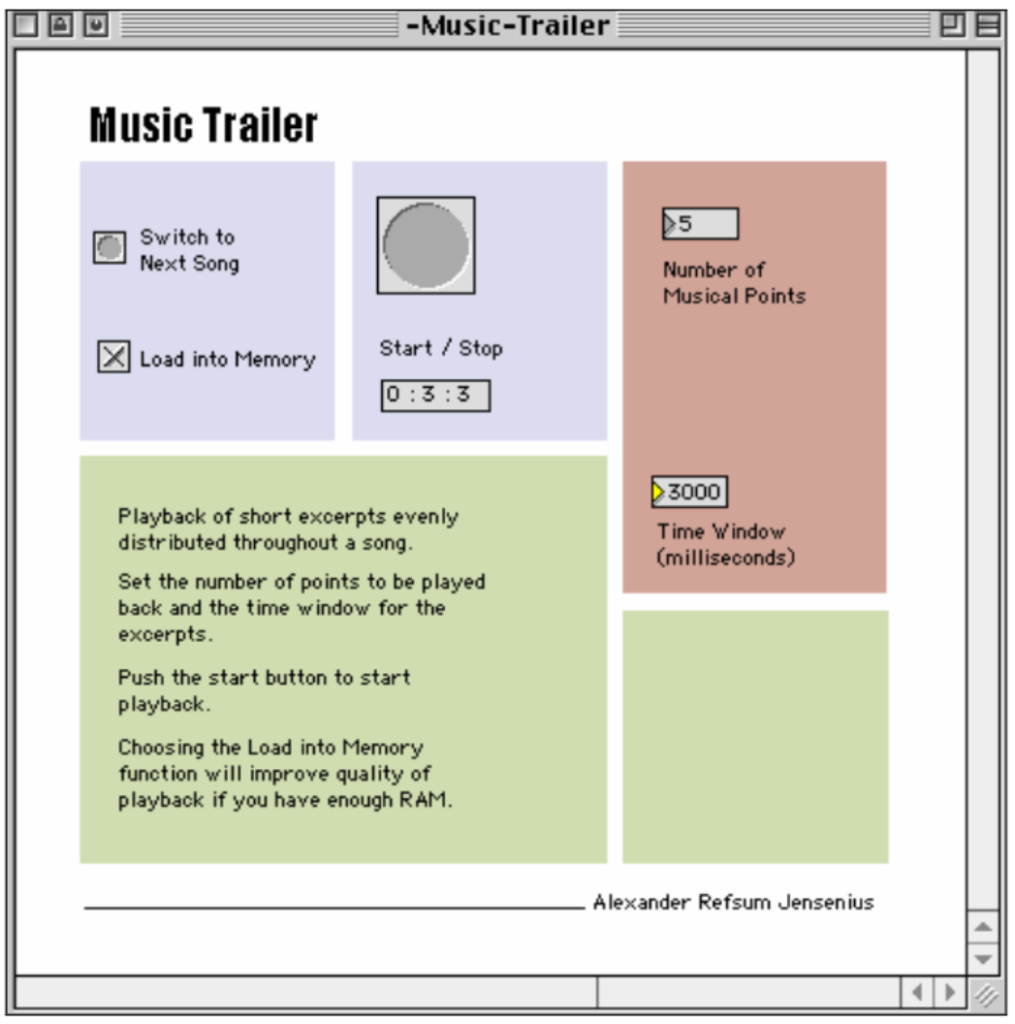
The patch allows the user to choose the number of segments that shall be played in the song, the window size, or each musical segment’s duration. The patch’s main technical feature is to find the length of the song and calculate the evenly distributed segments to be played.
Below are two examples, one made by sampling 5 excerpts each lasting 3 seconds, or 3 excerpts each lasting 5 seconds. These examples show that it is possible to hear some of the rhythmic figures, melody and timbre.
Even though the patch selects segments without any knowledge of musical content, I would argue that the result is more relevant than the compression example presented above.
Salient-based thumbnailing
However, the problem with this approach is that the program does not know anything about the musical content, and this lack of musical “knowledge” might result in missing out on perceptually relevant points. So music thumbnails would be much more useful if they were based on sampling salient features. This is a non-trivial task, and, obviously, I did not manage to implement this during my master’s. I did make a couple of saliency-based music thumbnails manually:
These two examples capture some of the song’s structure and parts of the melody while still preserving timbral qualities. I haven’t followed the research literature on audio/music thumbnailing very closely in recent years, but I am sure that someone has done a similar thing with AI now. If not, someone should do it!